
What is difference between Flutter and React frameworks for developing mobile app which is better
February 6, 2023
Godaddy Business Email Configuration Settings IMAP POP3 SMTP
May 3, 2024

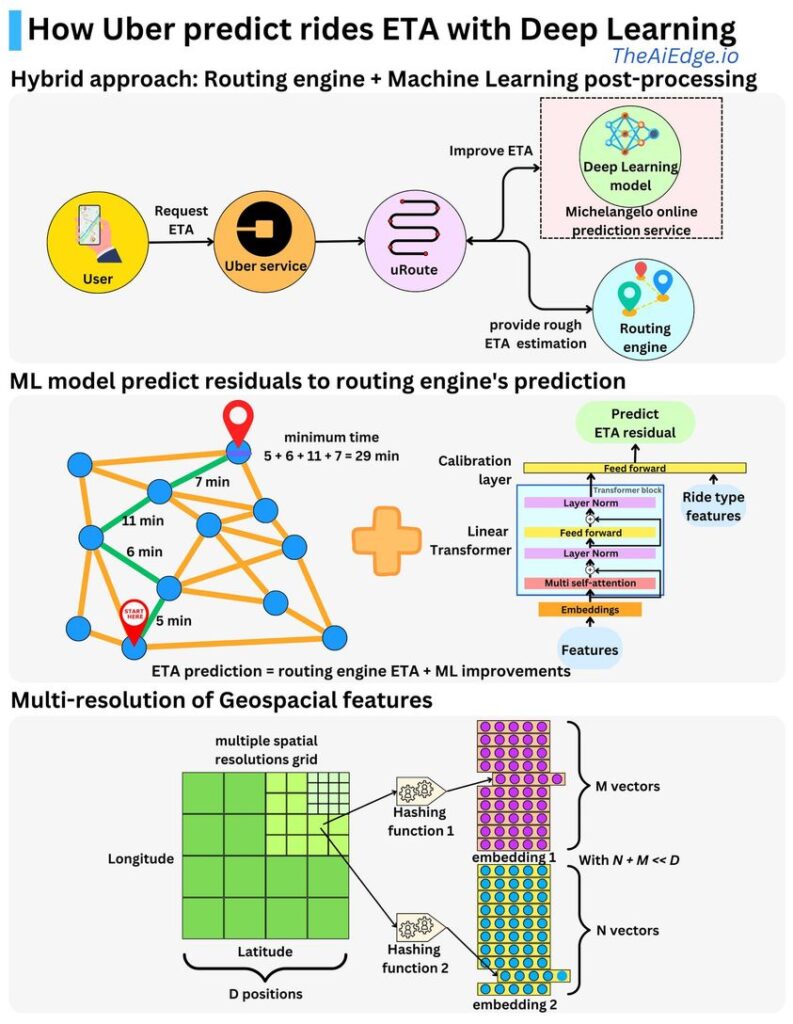
How does Uber predict ride ETAs? ETAs are used to compute fares so it is critical to be quite accurate. Interestingly enough, they used to have an XGBoost model predicting ETA but they built a Transformer model that outperformed it.
The Expected Time of Arrival (ETA) process starts when a user is looking for a car on the application. The ETA is provided to the user and is used to compute the ride’s fares. The process goes as follows:
– The user requests an ETA from the mobile application and it is sent to the Uber service
– The Uber service calls a routing engine to provide a rough estimate on the ETA.
– Uber uses a Deep Learning model that refines the routing engine estimate. The routing engine computes an estimate Y and the Deep Learning model computes the residual R of Y such that Y + R is a better estimate. So the target the model is learning is
R = Ground truth ETA – Y
– The model’s predictions are refined by considering the ride type (delivery trips vs ride trips, long vs short trips, pick-up vs drop-off trips).
– The prediction is served to the user in a few milliseconds.
Think of the routing engine as Uber’s version of Google Maps. Why can’t the routing engine be enough? The routing engine just computes the time to get from point A to point B, but an Uber ride is a bit more than that. We need to take into account the different drivers available nearby for the ride. We need to account for the difficulty of parking in the pick up location or destination. Also the routing engine is most likely not fully real-time and the machine learning model will be able to use real-time information about the traffic.
A routing engine works as follows:
– The different segments of road and intersections work as a graph. The intersections are the nodes and the road segments are the edges connecting them.
– Based on the current traffic information and the historical data, we produce a time estimate to go from one node to another neighboring node. Each road segment receives an edge weight that corresponds to those time estimates.
– We can now use a graph algorithm to find the path that minimizes the total time to go from the pick location to the destination.
The model consists of a Linear Transformer block followed by a feed forward network. A linear Transformer is a Transformer using a linear self-attention mechanism such that the attention weights are computed in a linear time. The feed forward network is used as a calibration layer to help generalize to all the different types of rides. Bringing the ride types features closer to the target allows the model to give more attention to those features.
The continuous variables are bucketized into categorical variables and each variable is associated with an embedding. The geospatial features are hashed at multiple resolutions into multiple embeddings with a small hash size for memory efficiency.


